| MARCOnI Dataset |
Introduction
MARCOnI (MARker-less Motion Capture in Outdoor and Indoor Scenes) is a new test data set for marker-less motion capture methods that reflects real world scene conditions more realistically, yet features comprehensive referecene/ground truth data. The dataset features multi-view video datasets of twelve real world sequences with varying sensor modalities, different subjects in the scene, and different scene and motion complexities. Our new multi-model dataset contains sequences in a variety of surroundings: uncontrolled outdoor scenarios and indoor scenarios. The sequences vary according to different data modalities captured (multiple videos, video + marker positions), in the numbers and identities of actors to track, the complexity of the motions, the number of cameras used, the existence and number of moving objects in the background, and the lighting conditions (i.e. some body parts lit and some in shadow). Cameras differ in the types (from cell phones to vision cameras), the frame resolutions, and the frame rates. Table 1 summarizes the specifications of each sequence. All data including original sequences and ground truth 3D joint positions will be made available to the research community through this webpage. Please note that all cameras are synchronized. In particular, the cell phone cameras and the GoPro cameras, that have no hardware sync, are synchronized up to frame accuracy using the recorded audio up to one frame's accuracy. Phasespace Vision cameras are pixel-synced in hardware. The data set is designed for versatile testing of a larged large range of algorithms, so some scenes are recorded with up to 16 video cameras. The dataset features reference 3D joint positions from 3 different reference sensor modalities, these are:
- A3D: Reference 3D joint positions are calculated based on manual annotation of the joint locations in each frame of video through Mechanical Turk users.
- MP: Some sequences were recorded with a PhaseSpace multi-view video system, and a synchronized Phasespace active-LED marker-based motion capture system calibrated to the same coordinate frame. 38 markers were worn on top of the normal clothing, from which reference marker-based joint positions were captured.
- DMC: For sequences filmed with a sufficiently dense set of cameras, 3D joint positions reconstructed with the baseline Sum-of-Gaussian based marker-less motion capture approach.
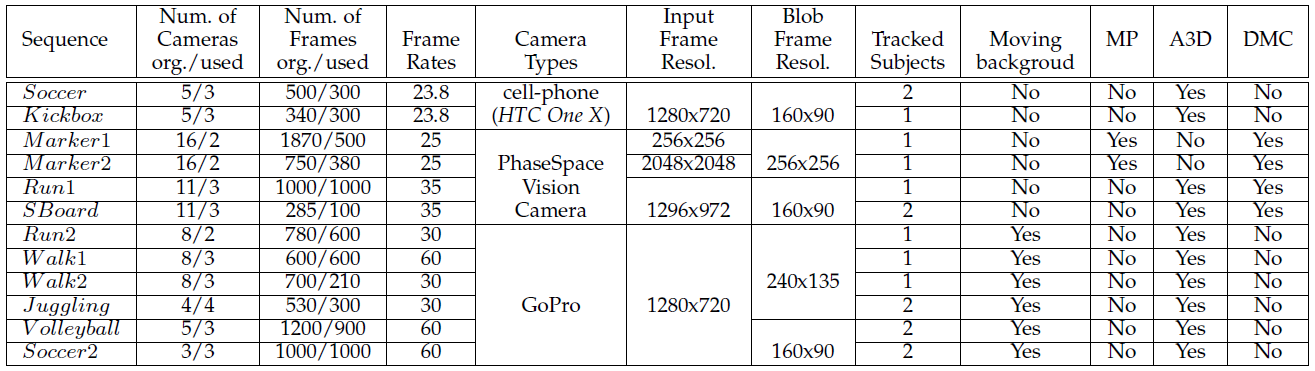
Table 1: Specification for each sequence in our multi-model dataset. We quad-tree downsample the input images to convert them into an image Gaussian representation, which yields the effective image resolutions listed in column Blob frame resolution. To test our new approach, we always only used a subset of 2-3 cameras for each scene, as denoted by used in columns two and three.
Use of the data set
The data may be used free of charge for non-commercial and educational purposes. For any other purpose you must contact the authors for permission. Also, if you use the data set you have to cite the following article.
Citing this work
@inproceedings {EEJTP15,
author = {A. Elhayek and E. Aguiar and A. Jain and J. Tompson and L. Pishchulin and M. Andriluka and C. Bregler and B. Schiele and C. Theobalt},
title = {Efficient ConvNet-based Marker-less Motion Capture in General Scenes with a Low Number of Cameras},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
month = {June},
}
|
Download
Below you can download the images, annotations, calibration and the CNN detections of each multi-view sequence:
| Soccer | Images | Annotations | Calibration | CNN Detections | Kickbox | Images | Annotations | Calibration | CNN Detections | SBoard | Images | Annotations | Calibration | CNN Detections | Soccer2 | Images | Annotations | Calibration | CNN Detections | Walk1 | Images | Annotations | Calibration | CNN Detections | Walk2 | Images | Annotations | Calibration | CNN Detections | Volleyball | Images | Annotations | Calibration | CNN Detections | Juggling | Images | Annotations | Calibration | CNN Detections | Run1 | Images | Calibration | CNN Detections | Run2 | Images | Annotations | Calibration | CNN Detections | Marker1 | Images | Calibration | CNN Detections | Marker2 | Images | Calibration | CNN Detections |
Data description
-
Images: the multi-view images of each sequence -
Annotations: 2D body parts annotations of each actor in each image stored in a matlab structure -
3D Markers: stores 3D markers data captured using a synchronized Phasespace active-LED marker-based motion capture system -
Calibration: intrinsic and extrinsic parameters of each camera -
CNN Detections: detection of each body part in each image is estimated using the convolutional neural network (CNN) algorithm used in our paper. The detections are stored as heatmaps (i.e. grayscale image)
Examples
Below we visualize few frames from selected sequences.






Team
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Ahmed Elhayek |
Edilson De Aguiar |
Micha Andriluka |
Jonathan Tompson |
Arjun Jain |
Leonid Pishchulin |
Christoph Bregler |
Bernt Schiele |
Christian Theobalt |
Publications
@inproceedings {EEJTP15,
author = {A. Elhayek and E. Aguiar and A. Jain and J. Tompson and L. Pishchulin and M. Andriluka and C. Bregler and B. Schiele and C. Theobalt},
title = {Efficient ConvNet-based Marker-less Motion Capture in General Scenes with a Low Number of Cameras},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2015}
month = {June},
}
|